
RODES - Replication On Demand System
(for DB Server Cluster Load Balance)
![]()
|
|
|
ABSTRACT Over last years, a significant growth of net traffic and processing load has been verified, mainly in the database servers. Many factors have been responsible by this growth, such as: growth on demand for availability of information, increase both of size as and volume of information storage, as we can verify in multimedia application, are that becoming more and more popular. One solution for the problem of processing large volume of information is the utilization of servers based on clusters, working together with distributed database systems. This type of union allows the parallel manipulation of great volumes of information. Although multiprocessing in clusters systems is, really, being used more and more due to high performance, low cost and high scalability characteristics, we verified that specific database systems for these architectures present some restrictions in relation to the data replication, and load balance, depending on the use of shared disks in cluster architecture. The main objective of this work is the study and implementation of a mechanism that allows a better cluster load balance, in periods of high demand for information, by replicating more requested data in a DDBMS. The complete process of copies generation is autonomous, with dynamic distribution of copies for the idle or less loaded node. Another considered point in this work is the search of better management of the available resources in cluster. This work presents the following as the main contributions:
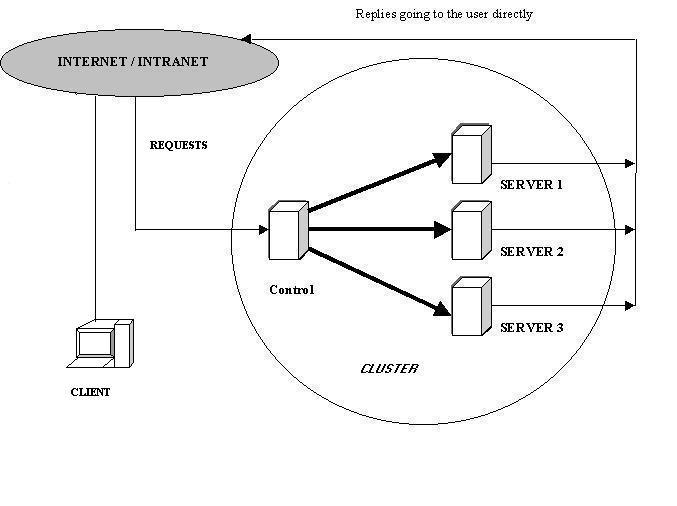
The adopted scenery for this work consists of a ANSI/IEEE SCI standard based cluster, composed basically of multiprocessing workstations, interlinked through a interconnection hierarchical system based on SCI connector keys. The configuration can vary between at least 3 and at the most 8 nodes for rack, one node being reserved for control (figure-1). The cluster has three interconnection nets: one primary for control (Fast-Ethernet 100BaseT with 100 Mb), one secondary for data (Myrinet with 180 Mb), and one tertiary optional for synchronization. We used LINUX REDHAT 6.0 (kernel - 2.2.5) as O.S. and DBMS Informix-DS LINUX Edition 7.30.UC5.
Figura-1: System model
The system considered in this work is a continuous media server, which is emerging in several areas of activity, and also, due to the considerable size of the documents it handles, will require better management systems. The implemented mechanism consists of metadata set control tables and management programs, that can be distributed or centralized according to the need and implementation type, seeking control and performance. The base of the mechanism is the measurement and analysis of each cluster server load. This analysis allows any node, when reaching a certain load value, beyond the threshold, to start a process to evaluate which of the documents it supplied is causing the load excess. After the document identification, some factors such as maximum service capacity of node, percentile of readiness of node, variation of net and disk taxes, and total amount of competitive accesses in a time lapse are considered. The document is replicated in two steps: in the first step is created one data copy in the smallest load or idle cluster node, in second step is created one metadata index copy in the control node. The preliminary results showed that this mechanism can allow, according to implementation, more or less node local autonomy over the documents for its management, as well as better performance in the cluster load balance. This work divides basically in two parts. The first part consists of a viability study and concept test implementation, that it is being concluded. The second part is the implementation of the mechanism in a DDBMS cluster operating as a continuous media server, inside of a virtual server model.
|
|
Copyright or other proprietary statement goes here.
|